
Fashion Captioning with BLIP Finetuning
Role: AI Engineering
Motivation
While recent image captioning models demonstrate strong general performance, they often fail to align with how people actually describe and interpret fashion images. Generic image captioning models tend to overlook domain-specific vocabulary, resulting in vague or inaccurate descriptions.
This project was motivated by the need for human-centered image captioning—captions that are not only accurate by metric standards, but also meaningful, accessible, and useful to real users.
Goal
- Improve the accuracy and contextual relevance of fashion image captions
- Enable the model to understand fashion-specific vocabulary and visual cues
- Explore the potential of domain-adapted captioning for real-world applications such as e-commerce and accessibility support
Methodology
To address the domain gap in existing captioning models, we fine-tuned the BLIP (Bootstrapping Language-Image Pretraining) model on a carefully curated fashion dataset.
Model Overview
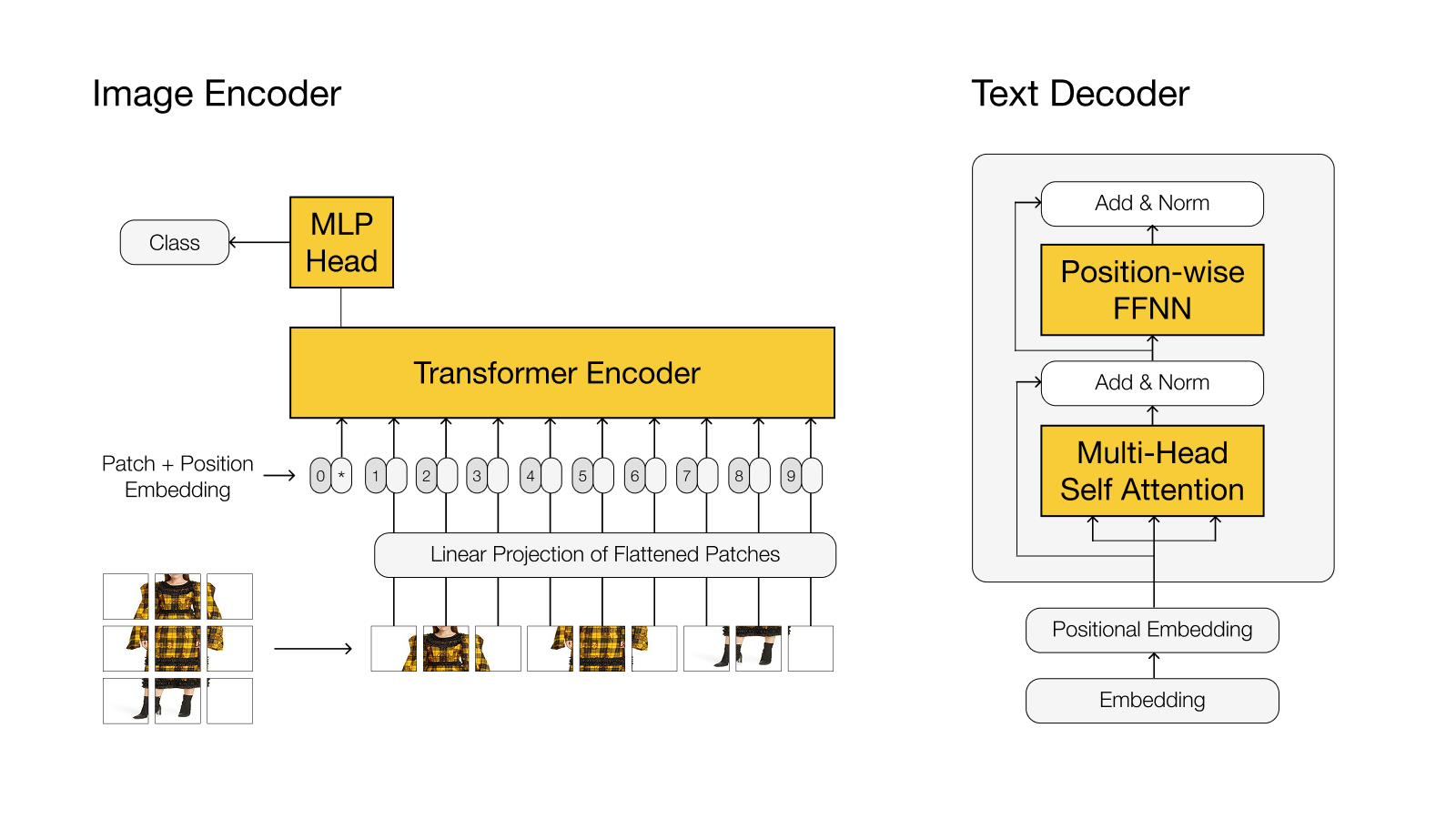
- Decoder-only
- For all layers of Decoder
- query/key/value of the attention layer
- dense layers (Feed-Forward Neural Networks)
- For all layers of Decoder
- Encoder + Decoder
- All layers of Decoder
- For the last 6 layers of Encoder
- query/key/value of the attention layer
- dense layers (Feed-Forward Neural Networks)
Quantitative metrics such as BLEU, METEOR, and CIDEr were used to assess technical improvements, while the broader goal was to improve caption clarity, descriptiveness, and interpretability for end users. By adapting the model to the fashion domain, the system was trained to move beyond generic descriptions and generate captions that better reflect the intent and details of fashion images.
Outcome
- Produced more human-readable fashion captions through domain-adapted fine-tuning
- Validated model performance using multiple quantitative evaluation metrics
- Highlighted practical value for real-world use, including e-commerce product descriptions, fashion content creation, and improved accessibility for text-dependent users
Reflection
This project strengthened my interest in human-centered AI, highlighting how model performance alone is insufficient without alignment to human language, expectations, and use contexts. It reinforced my belief that AI systems should be designed not just to perform well, but to communicate effectively with people.
If extended further, I would:
- Incorporate human evaluation to assess caption usefulness and clarity
- Study how different user groups (e.g. visually impaired users, online shoppers) interpret and rely on generated captions
- Explore bias and representation issues in fashion datasets to ensure inclusive outputs